[Since Comet 4.0.5 R20002] Images in InDesign® must be either available in the local network or embedded into the document. Images located in the internet can not be processed by InDesign®. With the plug-in URL Link and its panel Web Images the priint:comet plug-ins offer a possibility to use images from the net too. To do this, images are downloaded locally first and links are made to these files then.
Attention : Despite all efforts, it may happen that URLs cannot be resolved. Non-resolvable URLs are not subject of the WERK II support! Please feel free to contact our support in these cases, but please understand that we treat enhancements in this area as (chargeable) feature requests.
In order to keep connected, the frames will remember the URL and its Header information. This allows updating the images if they have been changed on server side.
Please pay attention to property rights and licenses of the used images.
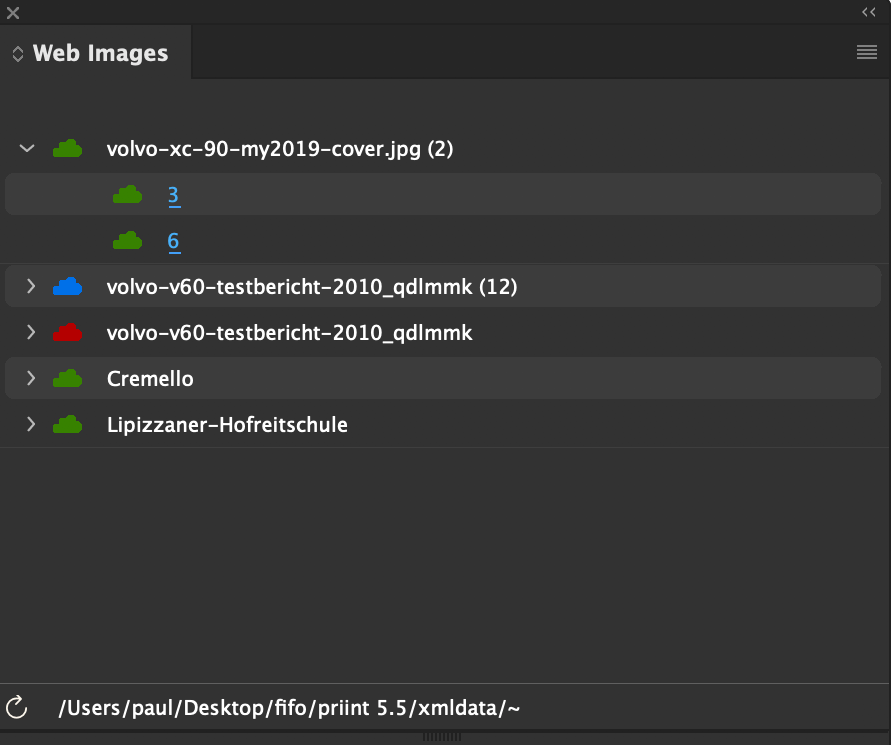
In the panel Web Images all Web images are shown together with the frames, using these images:
The states of the images are displayed by the cloud symbol:
Using the menu View -> Web Image State you can also display the states of the images at the document frames:

By double-clicking on the cloud symbols of the panel, current images (green) are checked again and changed images (orange) are reloaded.
Single clicking the page number selects the frame in the document. The following additional options are supported:
Using the fly out menus of the panel, the document's web images can be checked, updated and deleted. Individual images can be edited using the Web Images context menu.
To avoid unnecessary network traffic, status checks of the Web Images are only made on user requests. An automatic check is not made. With timer::document_start in the AfterLogin script (panel statement 92) you can easily configure an automatic check by yourself. Use document::check_url_links in the idle timer action to check the Web Images.
The data required for the Web Images can be displayed in the panel Plug-Ins -> Comet Admin -> Frame Tags. To do so, hold down the SHIFT key and click on the magnifying glass in the upper right corner of the panel.
Using the default location docname_Links next to the document for image downloads requires, that the document must be saved at least once. Otherwise the document has no file path. See here for more informations.
To manually create a Web Image, proceed as follows:
The cScript function frame::image, image placeholders and the TaggedText-Tags <in>, <w2inline> and <graphicell> automatically checking the given image paths. If they see an URL, they creating Web Images by default.
Using URL events, you may configure your system in a way, that well known URL drop downs will create Web Images. A complete example you will find here.
The following rules are used for the placement of Web Images into the image frame:
When creating Web Images with script functions such as frame::image or with the help of <w2inline> tags in TaggedText, the placement instructions (position, scaling, ...) specified in the call are used, regardless of whether the target frame already contains an image or not.
When creating Web Images manually using the Edit -> Paste Comet Image menu, the settings of an existing image are used. If the target frame is empty, the image is inserted centered with max. 100% scaling. Images that are larger than the target frame are scaled down accordingly.
When updating Web Images, the image settings of any existing image are prefered. Only a possible adjustment of the frame size to the image size (generally through a negative alignment) is applied. Attention: Each time the new image becomes smaller, the frame also becomes smaller, but it never becomes larger.
The original placement instructions are only applied if the image frame is empty.
The following protocols are supported for downloading images:
Possibly required login data are specified according to the URL syntax, e.g.
http://paul:password@www.hi13.de/aaa.png
Passwords within the URLs are stored encrypted and enclosed by /// into the document and are automatically decrypted if required.
Images provided by a PubServer can usually only be accessed via the connection's REST Connector. To load these images, the Content System of the PubServer generates special so-called Media Proxy URLs. The first parameter of these Media Proxy URLs is always called downloadUrl and contains the URL conform encoded URL of the media data (the image).
Here is an example of a correctly formatted Media Proxy URL:
https://pubserver.com/rest-connector/mediaproxy/example/myDownload/0815?downloadUrl=https%3A%2F%2Fpim.com%2Fimages%2F0815.png%3Fsize%3D480x640
Media Proxies are usually protected against unauthorized access and require a valid PubServer SessionID for authentication. When downloading Web Images from Media Proxies, the current sessionID is therefore automatically included into the call as the named cookie PubServSessID. ((As a trick, you can log in into another InDesign and write the SessionID of that connection into the $DESKTOP/sessionid.h file. Then this SessionID will be used).)
If there is no PubServer connection, the download of Media Proxies will fail.
Attention: To avoid errors in the URL encoding of PubServer URL and DownloadUrl, the PubServer URL (i.e. the part of the Media Proxy URL before ?downloadUrl=http ) must not contain any unencoded URL special characters except / and :!
If all or part of your Internet access is controlled by a proxy, the proxy settings must also be known to the Web Images. To do this, select the Proxy... flyout menu of the Web Images panel. In the dialog that appears, you can specify the proxy settings. The proxy settings are active even after restarting the program. The address of the active proxy is displayed behind the Proxy | menu name.
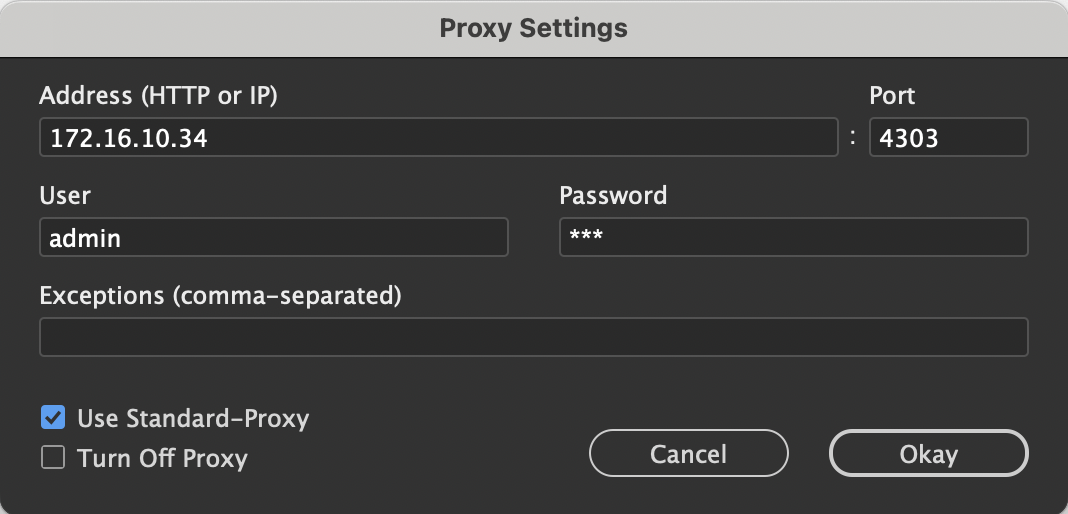
As an alternative to the Proxy Dialog, the proxy can also be edited with the following script functions. Here, too, the settings made are restart-resistant and active in particular even after the current data connection is disconnected:
Image URLs can contain session IDs and other time-limited information. Here is an example:
The image URL contains the parameter session, which is checked by the server www.company.com. If the session is invalid or has expired, the server does not (or no longer) deliver the image:
https://www.company.com/service/object_image/get?id=...&session=8bed0851-dad5-41b5-bcca-c2b7d3e888dc&p2=12
This means that Web Images with volatile parts in the URLs have two problems:
The solution is obvious: The volatile parts of the URL must be replaced by fixed information that allows the volatile parts to be recalculated when the image is checked and/or loaded. To solve this, we have introduced a new 'function' with which the volatile parts of the URL can be recalculated and replaced if necessary:
getSessionData(name,attribute)
The name getSessionData is fix. name and attribute are defined so that the replaced volatile value can be recalculated. The specification must not contain whitespaces !
The above URL must therefore be changed as follows:
https://www.company.com/service/object_image/get?id=...&session=getSessionData(paul,session)&p2=12
The now fixed image URL is saved in the frame of the Web Image. If the image is to be loaded or checked, getSessionData(name,attribute) is recalculated first and then replaced by its current value. The following describes how the recalculation is configured.
To determine the current value of getSessionData, the server must first be queried. You need two things for this:
This information you must request/get from the IT department of the company that operates the server of the image URL. Then enter the data received in the file sessions_data.xml. sessions_data.xml is searched for in the following places:
Entries for session-dependent values must have the following format:
<sessions> <session> <name>Unique-Name<name> <url>https://www.priint.com/service/usermanagement/login<url> <data> { "username": "uname", "password": "***", "clientType": "Web", "language": "en_US", "token": null, "connectorName": "default" } <data> <session> <!-- More Entries --> <sessions>
Web Images can use this information to compile and execute an automatic server request. In CURL notation, the request corresponds to the following Terminal instruction:
curl -X POST url -H "Content-Type: application/json" -d data
The server response to this request must contain all necessary volatile information. The response format must be JSON!
A valid answer could look like this, for example:
{
"session" : "ab96150a-36e3-4880-87fc-10d23644aaaa",
"userId" : "03b83f47-0c76-426a-a2e5-b24c1c8a7c04",
"language" : "en_US",
"message" : null,
"code" : 0
}
In a the second step, the desired current value of the given attribute is determined using the attribute parameter from getSessionData:
By specifying getSessionData(paul,session) in the image URL, we obtain the value ab96150a-36e3-4880-87fc-10d23644aaaa from the above response and the currently applied URL changes as follows:
https://www.company.com/service/object_image/get?id=...&session=ab96150a-36e3-4880-87fc-10d23644aaaa&p2=12
With this URL the image can now be loaded and checked and the URL will be automatically recalculated at subsequent usages.
Sometimes it is necessary to add further information to a URL in the so-called HTTP header. In curl notation, this corresponds to the -H option. To do this, please proceed as follows:
Create a uniquely named entry in the sessions_data.xml file for each collection of required HTTP headers. The entries may each specify any amount of header data and must have the following syntax:
<session>
<name>myName</name>
<header>headerData_1 OR ##actionID</header>
...
</session>
The specification can be either a direct value, e.g. Content-Type: application/png or an actionID of your data pool given by a trailing ##.
Please note that if you use actions, your image URL will load different (or no) images when you disconnect the data connection!
The following variables are defined in the script:
| Variable | Kind | Type | Description |
| gURL | r/o | char* |
Current URL |
| gName | r/o | char* |
Name of Header data |
| gHeaderData | w | StringList | Results list. Enter all the header data you want in this list. |
Here's an example of a script:
#pragma plain
#include "internal/types.h"
int main ()
{
wlog ("", "___UU (%s)\n", gURL);
wlog ("", "___NN (%s)\n", gName);
stringlist::append (gHeaderData, "AAA: aaa");
stringlist::append (gHeaderData, "BBB: bbb");
return 0;
}
This script may also be a Python Script. More information can be found here.
Here's an example of a Python script:
#!py
#pragma plain
import comet
def main():
comet.wlog(f'___UU ({comet.gURL})')
comet.wlog(f'___NN ({comet.gName})')
comet.setOutput('gHeaderData', ['AAA: aaa', 'BBB: bbb'])
return 0
For each required collection of HTTP header data, insert the following pseudo function at any location but in exactly this notation and without any additional spaces:
=getHeaderData(myName)
Here's an example:
http://www.hi13.de/aaa.png=getHeaderData(pp)
or (e.g.)
http://www.hi13.de=getHeaderData(pp)/aaa.png
InDesign® expects images to exist as local files. Complete paths within the local network and image paths 'next to' the document are permitted. As long as another network has the same image folders, image links of a document can also be resolved from there. Links to images 'above' a document can only be resolved in other networks if UNC paths are used!
Images outside the local network are not supported by InDesign®. (But your browser doesn't do that either, it also has to load every image first). So in order to support Web Images, we must first download the images locally. The following options are supported for the download folders:
The download paths including file names of the images must not be longer than 260 characters!
Note: For longer paths, you can try to shorten the name of the download file using the
NAMEFLAGS of the Customized Name.
As of v4.3 R35410, paths of any length and only
limited by the respective operating system are supported.
Nevertheless, the names of the download files must not be longer than 255 characters.
If the download name would be longer than 255 characters even after applying any //// hints,
the MD5 hash of the original URL plus _name_too_long plus any file extension is used automatically.
The default folder for the download is the folder
DoumentName_Links
next to the document. If the folder does not exist, it is created automatically.
For relative image references to work, the document must have a path. New documents must therefore have been saved at least once!
Using panelstatement 141 you can provide a script that calculates a path for the download folder according to a given URL. If the
| Variable | Data type | Type | Description |
| gDestFolder | String | out |
Enter the desired destination path here. Please note that the variable is of type String and not char*!
|
| gURL | char* | in |
Full URL of the image |
| gDestName | char* | in | |
| gDocumentID | char* | in |
Document ID of the current document Hinweis: The document ID is provided to make your work easier. To get more information about the current document please use the appropriate document functions. |
Here's an very simple example:
int main ()
{
if (!system::is_server ()) string::set (gDestFolder, "/Volumes/Images");
else string::set (gDestFolder, "/Volumes/Images_%s", server::get_session_arg ("-configuration"));
return 0;
}
As of v4.3 R36308, you can also use a shared download folder for all instances. For more information see here.
int main ()
{
string::set (gDestFolder, "/Volumes/Images");
prefs::webimage_enable_locks (1);
return 0;
}
If nothing else is specified, the MD5 Hash Code of the image URL is used as the file name for the download. In addition, a Name Suffix for the image is searched for after the domain and path of the image URL. If a 'name' is found, it is appended to the hash code (separated by _) and used as the Display Name in the Web Images panel too.
Names of downloaded Web Images usually have no or possibly even wrong file extensions.
There are two reasons for the naming with hash codes:
The image names found in the URLs can often be quite technical or long. In addition, missing or inappropriate file extensions, while not a problem for image rendering in the plugins and InDesign®, can interfere with use in third-party programs. Here is a screenshot of the names of two such URLs:

To avoid these problems, you can add display and file name information to your actual image URL. To do this, add the separator //// at the end of the URL. After the separator, you can specify your own display and file names. These specifications are removed for loading the image files. The following general syntax is expected:
url////displayName | url////--fileNameOptions | url////displayName--fileNameOptions
The following table describes the information in detail:
| URL | Display Name | File Name | Remarks |
| http://www.hi13.de/schnipp | schnipp | 163...f8_schnipp |
A name was found at the end of the URL. The found name is appended to the MD5 hashcode of the URL separated by _. But please take care : Since the name has no file extension, the loaded file also remains without extension and the use of the image file in third party programs may be restricted. |
| The same URL http://www.hi13.de/schnipp is always used in the following descriptions. | |||
| ...////My Title | My Title | 163...f8_schnipp |
The text that follows directly after the //// separator is used as the Display Name in the Web Images panel. Here you can find more information about the Display Names. The name of the image file is left untouched by this specification and therefore remains in this case without file extension. |
| Details of the //// definition separated by '--' are used to determine the download file. | |||
| ...////--NAMEFLAGS | schnipp |
for example for kNoHash : schnipp
for example for kOnlyHash : 163...f8 |
Use the name given in the URL. The part after the last / of the URL is used as the name. The following keywords are supported:
The display name may be empty. In this case the separator '--' directly follows the '////' at the end of the URL. |
| ...////--gif[NAMEFLAGS] | schnipp.gif | 163...f8_schnipp.gif |
Change/Append the file extension only. The given extension is appended to the display name too. In addition, the flags described above may be added to shorten the filename, e.g. ////--gif+kNoHash. The display name may be empty. In this case the separator '--' directly follows the '////' at the end of the URL. |
| ...////My Title--gif[NAMEFLAGS] | My Title | 163...f8_schnipp.gif |
Change display name and file extension. In addition, the flags described above may be added to shorten the filename, e.g. ////My Title--gif+kNoHash. The display name follows directly after the //// separator. Then, delimited by '--' from the display name, the file extension follows. |
| ...////My Title--!myImage.gif | My Title | myImage.gif |
Change both, the display name and the filename of the image file. In this case you must ensure the uniqueness of the file names yourself! Using '--!' you change the complete name of the downloaded image file. |
| ...////My Title--!A/B/myImage.gif | My Title | myImage.gif |
A relative path may be specified before the filename. The image is then placed in the specified subfolder of the current download folder. In this case you must ensure the uniqueness of the file names yourself! The subpath must not contain any .. folders. If the folder does not exist yet, it will be created automatically. |
| ...////My Title--!/A/B/myImage.gif | My Title | myImage.gif |
An absolut path may be specified before the filename. The image will then be placed in the specified folder (and not in the current default download!). The path may start with a defined $alias.. In this case you must ensure the uniqueness of the file names yourself! You need the appropriate write permissions! If the folder does not exist yet, it will be created automatically. |
In general, the following applies to the names:
Display names are translated into the current InDesign® language by the general translation process.
Thus, ...////reference results in the display name Reference in a German InDesign® but in Reference in an English InDesign®.
Using the prefix notrans_ you can suppress the translation. ...////notrans_reference results in the display name reference in every InDesign® language then.
Display names can contain any number of $key$ specifications. Each single key is sent through the translation process one by one and replaced accordingly.
Thus, ...////$Image$ 1 results in the display name Bild 1 in a German InDesign® but in Image 1 in an English InDesign®.
The display name is only valid for this one frame.
Newly added Web Images without display names are not named automatically, even if there are already web images with the same URL!
No checkings are made for uniqueness. If different URLs are using the same display name, the frames will appear with the same display name in the panel.
If the same image is named differently in different frames, the first name found is displayed in the panel and the sub-entries with different names are • appended by their differing names.
The InDesign® standard panel Links will still display the names of the local files of course.
Display names can also be set or changed after loading the images. The following options are available:
If you defined your own file names using !--, you have to take care of the uniqueness of the file names yourself! Non unique names will lead to errors when using and checking the images.
[since v4.2 R32690] Instead of a filename, a relative or full path can also be specified. Relative paths are resolved within the current download folder. Full paths may start with defined $ALIAS names. Missing folders are created automatically. The etags folder is always created in the lowest subfolder.
The following characters are forbidden in file names at least under Windows and are each replaced by '-' (minus). For compatibility reasons, the same replacements are made under Linux and Mac OS.
< > : | ? *
Subsequent changes of file names should be avoided! The renaming leads in any case to the fact that the link becomes out of date and must be reloaded.
As of v4.3 R35410, paths of any length and only limited by the respective operating system are supported. Nevertheless, the names of the download files must not be longer than 255 characters. If the download name would be longer than 255 characters even after applying any //// hints, the MD5 hash of the original URL plus _name_too_long plus any file extension is used automatically.
[Since v4.3 R36308] If several instances of InDesign®-Server and/or comet_pdfs are working simultaneously and all are to use the same download folder, it will inevitably happen that two different processes want to write the same download file at the same time. This of course will not work. To prevent such conflicts, the downloads can block the target file for all competing processes on the same computer until their own target file is ready. All other processes that want to write the same file must wait for the blocking to end. Only then do these processes continue to run. In most cases, namely when the first download was successful, these processes can access the target file without further downloads then. The automatic blocking of the Web Images target files not only save a lot of disk space, but also time.
For reasons of backward compatibility, the blocking of URL downloads is not automatically activated. With the following instruction, e.g. in the after-login script (panel statement 92) you can activate automatic blocking:
prefs::webimage_enable_locks (1);
The following script commands are available for locking URLLink downloads:
For each URL, the server also provides so-called header information. These headers usually contain information about the file date, the size of the file and usually a so-called ETag. Header information are usually no longer than 500-1000 bytes. If a Web Image is changed on server side, the header information will be adjusted accordingly.
When loading a Web Image from the server, the current header information are loaded in addition to the actual image data automatically. In order to check the current state, it isenough to download the current header information only and compare them with the stored header information.
The following header information data is used for comparison:
No binary comparisons of the images are made. Manual changes to the local images do not affect the status of a Web Image!
Header information are stored in the sub folder etags of the image downloads. If the header information are missing, the image is downloaded always.
Unfortunately, it is not sufficient to store the header data in the respective image frame. Imagine the following situation:
Now there are two ways:
Embedded images are loaded from the server just like normal images. But after the downloaded image is embedded, however, it is automatically deleted immediately. Header information are stored in the frame itself.
If the updated image has the same proportions as the currently embedded image, the local geometry changes are restored on the image (image position, rotation, scaling, skew angle). When the aspect ratio is changed, the image is placed with the original placement guide (left-top, top-center, ...). Other images embedded with the same URL will not updated.
Note: In order to have the lowest possible UPLOAD traffic, embedded Web Images should be deleted before the InDesign® documents are sent, and be reloaded at the destination (now with download speed).
When opening a document, all Web Images contained in the document are automatically checked: If the local (downloaded) image file is missing, the image frame gets the state Unknown (blue). For performance reasons, the system does not check whether the local file is still up-to-date and missing images are not loaded automatically. The same applies to copy/paste and snippet placements. Here too, the system only checks whether the local image file is available.
When dragging and dropping between open documents, no Web Image checking is performed!
Please note that even when inserting templates during product build ups etc., the Web Images inside the templates are not automatically reloaded. If your templates contain static Web Images, these images must be reloaded as needed by using appropriate script functions or manually.
The following functions are implemented to support Web Images: